安装
直接使用brew安装即可:
brew install mysql
安装成功后,如果命令行是bash的话,使用source ~/.bash_profile重新执行下环境变量。如果使用的是zsh,那么使用source ~/.zshrc重新执行,让环境变量生效。
Ps: 如果有在.zshrc文件中使用srouce ~/.bash_profile命令的话 就可以使用source ~/.zshrc,如果没有 则直接使用source ~/.bash_profile即可。
安装成功后,可以使用以下命令启动或者关闭服务:
mysql.server start # 启动服务
mysql.server stop # 关闭服务
启动成功后,使用命令mysql -uroot直接进入数据库,如果有设置密码的话,使用命令mysql -uroot -p,然后按提示输入密码即可。
忘记密码
如果忘记密码或者要设置用户的登录密码,可以使用命令重置密码:
alter user 'root'@localhost IDENTIFIED mysql_native_password by '你的新密码'
可以使用mysql的GUI工具进行操作,比如navicat mysql或者官网提供的mysql workbench。
简单查询
所谓的CURD就是我们平时所说的增(Creat)、删(Delete)、改(Update)、查(Read)。
先增加一张表:
show databases; # 显示当前所拥有的数据库
use demo; # 进入demo数据库
# 创建一张book_categories表
CREATE TABLE `book_categories` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`category_name` varchar(50) DEFAULT NULL,
`created_at` datetime DEFAULT NULL,
`updated_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=39 DEFAULT CHARSET=utf8;
常用的简单查询有:
select * from book_categories; # 查询书籍分类表的所有数据
select id, category_name from book_categories; # 查询并列出表的id和caetgory_name字段
select id, category_name from book_categories where id > 2; # 查询表中id大于2的数据,并显示id和caetgory_name字段
select id, category_name from book_categories where category_name like '云%'; # 查询表中分类名称以云开头的数据,同理,还有%云-以云结尾的,%云%-带有云字的。
select id, category_name from book_categories order by id desc; # 查询结果以id降序排列
select * from book_categories having id > 3; # 查询id大于3的所有数据
select * from book_categories group by category_name; # 以category_name对数据进行分组统计
having 和 where 的区别
having的判断是数据分组前,通常和group by一起。where的判断是数据读入内存的时候。having可以使用字段别名,而where不行。比如:
# 使用having没问题,使用where会报name无法识别的错误。
select id, category_name as name from book_categories having name = 'xxx';
having可以使用统计函数,而where不行。比如:
select * from book_categories group by category_name having count(*) > 1;
数据添加的语句:
insert into book_categories (category_name) values('玄幻'); # 增加一条记录 - 指定列名
# 或者可以使用
insert into book_categories values(0,'玄幻', '', ''); #第一个属性如果为id自增的时候,可以直接设置成0
数据修改的语句:
update book_categories set category_name='言情' where id = 1; # 修改id为1的数据的分类名称为言情
# 如果不指定条件 则更新该表中的所有数据
update book_categories set category_name='言情'; # 修改表中所有数据的分类名称为言情
# 替换数据
update book_categories set category_name = replace(category_name, '言情', '历史'); # 批量修改表中所有分类名为言情的数据为历史, 如果指定修改 则加入where条件判断即可
数据删除的语句:
delete from book_categories; # 删除分类表中的所有数据
delete from book_categories where id = 2; # 删除id为2的数据
truncate table book_categories; # 删除分类表的所有数据
truncate 和 delete 的区别
两者都是删除表的所有数据,具体区别如下:
delete可以删除单条,指定where条件即可,且删除后可以回滚。truncate只能删除整表,且操作不可回滚。delete删除后再新增数据,自增 id 总是以总数据的长度+1 进行自增,而truncate从 1 开始。delete每次操作后都会有日志记录,而truncate不会。truncate的执行效率比delete高。
多表查询
先建立两张表:
# user 表
CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`age` int(3) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=39 DEFAULT CHARSET=utf8;
# product 表
CREATE TABLE `product` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`product_name` varchar(50) DEFAULT NULL,
`nums` int(11) DEFAULT NULL,
`owner` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=39 DEFAULT CHARSET=utf8;
并插入若干数据:
user 表:
| id | name | age | description |
|---|---|---|---|
| 1 | 张三 | 18 | 我是张三 |
| 2 | 李四 | 22 | 我是李四 |
| 3 | 小六 | 24 | 我是小六 |
| 4 | 王五 | 16 | 我是王五 |
| 5 | 小七 | 21 | 我是小七 |
product 表:
| id | product_name | nums | owner |
|---|---|---|---|
| 1 | 苹果 | 23 | 张三 |
| 2 | 梨子 | 15 | 李四 |
| 3 | 葡萄 | 27 | 小八 |
内连接
# 检索有水果产品的用户
select name, product_name, nums from user, product where user.name = product.owner;
# 或者使用内连接
select a.name, b.product_name, b.nums from user as a join product as b on a.name = b.product_name;
得到结果为:
| name | product_name | nums |
|---|---|---|
| 张三 | 苹果 | 23 |
| 李四 | 梨子 | 15 |
会发现,得到的结果是两张表共有的数据,而非共有部分则会省略,所以JOIN(INNER JOIN)是获取两张表的交集,如下图:

左连接
先上sql:
# 以左表为基准,获取用户的产品情况
select a.name, b.product_name from user as a left join product as b on a.name = b.product_owner;
得到的结果为:
| name | product_name |
|---|---|
| 张三 | 苹果 |
| 李四 | 梨子 |
| 小六 | NULL |
| 王五 | NULL |
| 小七 | NULL |
会发现,左表的数据全部出来了,而右表就显示了与之相关的数据,没有的则显示为NULL,所以左连接,简单点说,就是以左表为基准(left join左边为左表),获取右表与之相关的数据,可以用以下图来解释:
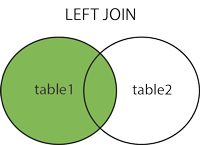
右连接
老规矩,先上sql,把左连接的sql修改下:
# 以右表为基准,获取产品的所属情况
select a.name, b.product_name from user as a right join product as b on a.name = b.product_owner;
得到的结果为:
| name | product_name |
|---|---|
| 张三 | 苹果 |
| 李四 | 梨子 |
| NULL | 葡萄 |
结果刚好和左连接相反,把右表的数据完全显示,然后左表显示与之相关的数据,没有则显示NULL,这里要注意的是,和它名字一样,右连接right join右边的为右表,而不是左,如下是与之匹配的图:
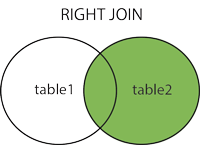
小提示
右连接在实际场景中很少用到,别问我为什么,后端小伙伴这么和我说的 😂,而一切的右连接都可以转化为左连接。
分组
使用Group by可以对数据进行分组,我们给product表再加点数据:
| id | product_name | nums | owner |
|---|---|---|---|
| 1 | 苹果 | 23 | 张三 |
| 2 | 梨子 | 15 | 李四 |
| 3 | 葡萄 | 27 | 小八 |
| 4 | 桃子 | 27 | 小八 |
| 5 | 菠萝 | 27 | 小八 |
然后我们统计下每个人所拥有的产品数:
# 统计每个人所拥有的产品数
select owner, count(product_name) as total from product group by owner;
会得到以下结果:
| name | total |
|---|---|
| 张三 | 1 |
| 李四 | 1 |
| 小八 | 3 |
上面的例子就是以owner(所有者)来进行数据分组,使用Count来统计每个人所拥有的产品数,除此之外,还可以使用Avg、Sum等统计函数。
索引
索引是一张表不可或缺的一部分,因为给一张表建立个索引,可以加快sql查询时的效率,这对一些大型查询来说,是必要的。
一张表可以建立一个索引,也可以建立多个索引。索引还分单列索引和组合索引,单列索引即一个索引包含一个列,一张表可以有多个单列索引,而组合索引是一个索引包含多个列
建立索引的方式:
# 创建数据库时建立
create table demoTable(
id INT(10) NOT NULL,
username VARCHAR(50) NOT NULL,
INDEX [name] (username)
)
# 如果表已经创建了,额外注入索引
create index name on demoTable(username);
# 或者
alter table demoTable add index name(username);
删除索引可以使用:
drop index [name] on demoTable;
索引的缺点
虽然索引能加快我们检索的效率,但如果对表进行修改操作,比如删除、更新、插入时,这时的效率就会大大降低了。因为之前也说了,索引页是一张表,我们对实体表进行修改时,mysql内部也会去更新索引表。
建立索引会占用磁盘空间,所以也不宜过过多的建立索引,造成滥用。
todo
- 事务
- 子查询
- union [all / distinct]
- 触发器
- 函数
- 存储过程